- Published on
GPT-5.4, "AI 직원"의 탄생인가 — 아니면 또 한 번의 과대포장인가
- Authors
- Name
2026년 3월 11일 | AI 모델 전쟁의 새 국면
3월 5일, OpenAI가 GPT-5.4를 내놨다. 공교롭게도 그 이틀 전에는 ChatGPT 사용자 이탈이 295%나 급증했다는 보도가 나왔고, 미 국방부 계약 논란으로 #QuitGPT 캠페인에 100만 명이 넘는 서명이 몰렸다. Anthropic CEO 다리오 아모데이는 같은 계약을 두고 OpenAI의 공식 입장을 "완전한 거짓말"이라고까지 표현했고, Claude는 앱스토어 1위에 올랐다. 타이밍이 절묘하다. 위기에 몰린 OpenAI가 꺼내든 카드가 바로 이 모델이라는 이야기인데, 그래서 더 냉정하게 뜯어볼 필요가 있다.
GPT-5.4의 캐치프레이즈는 "전문가 업무에 최적화된 가장 강력하고 효율적인 프론티어 모델"이다. 한마디로, 이제 AI가 엑셀 시트도 만들고, 브라우저도 직접 클릭하고, 프레젠테이션도 뚝딱 만들어내겠다는 선언이다. GPT-5가 처음 나왔을 때 Reddit에서 "역대 최악의 출시"라는 글이 수천 개의 공감을 받았던 걸 기억하는 사람이라면, 이번에는 분위기가 좀 다르다는 걸 체감할 수 있을 것이다.
뭐가 달라졌길래 5.3을 건너뛰고 5.4인가
이번 버전의 가장 큰 변화는 모델 통합이다. 기존에는 추론용(GPT-5.2 Thinking), 코딩용(GPT-5.3 Codex)이 따로 있었다. GPT-5.4는 이 둘을 하나로 합쳤다. 같은 대화 안에서 계약서를 분석하다가 코드를 짜고, 엑셀 시트를 만들고, 슬라이드 덱까지 뽑아내는 게 가능해졌다는 뜻이다.
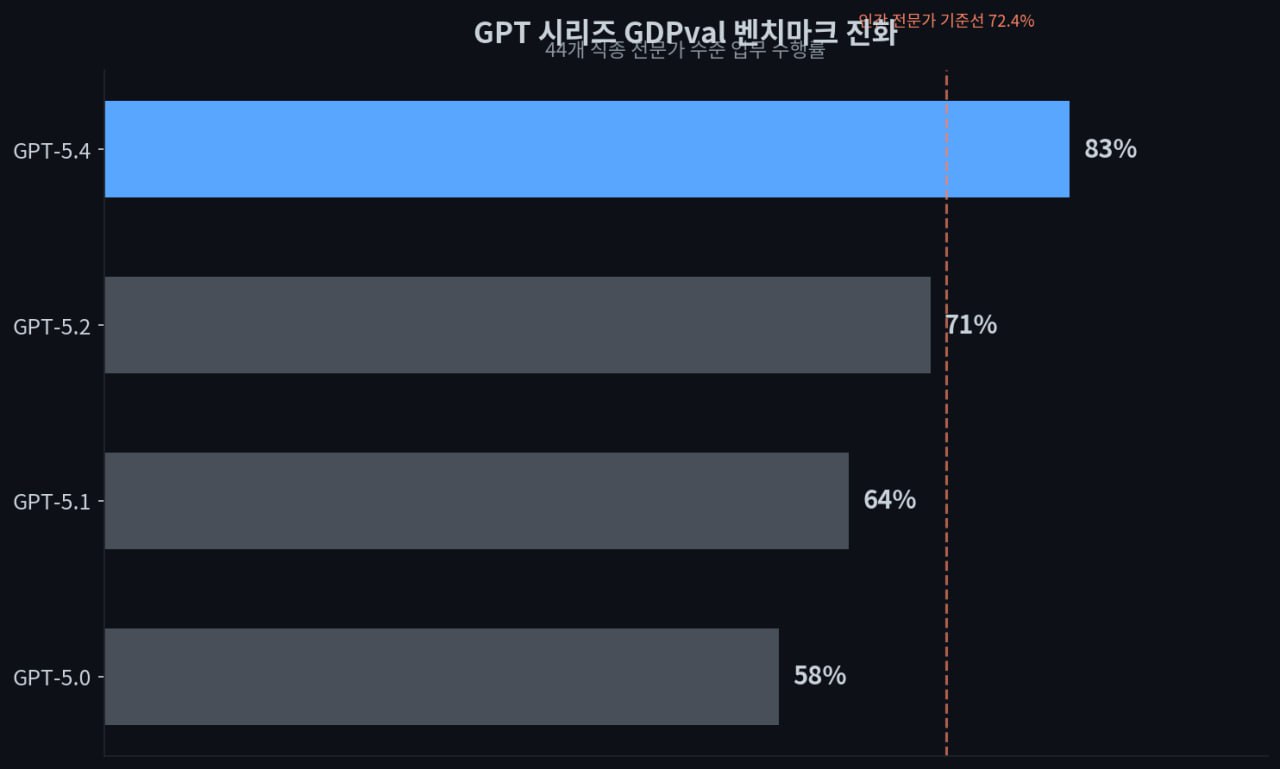
숫자로 보면 꽤 인상적이다. 44개 직종의 실제 업무를 AI에게 시켜보는 GDPval 벤치마크에서 GPT-5.4는 **83%**를 찍었다. 전작 GPT-5.2의 71%에서 12%포인트 뛰어오른 건데, 법률 문서, 엔지니어링 설계, 고객 지원 같은 현실의 업무에서 전문가와 동급 또는 그 이상의 성과를 냈다는 소리다. 투자은행 주니어 애널리스트 수준의 스프레드시트 모델링에서는 87.3%까지 나왔다.
 GPT 시리즈의 GDPval 점수 변화. 5.4에서 처음으로 인간 전문가 기준선(72.4%)을 크게 넘었다
GPT 시리즈의 GDPval 점수 변화. 5.4에서 처음으로 인간 전문가 기준선(72.4%)을 크게 넘었다또 하나 눈여겨볼 게 컴퓨터 사용 기능이다. GPT-5.4는 OpenAI 범용 모델 중 최초로 스크린샷을 보고 마우스를 클릭하고 키보드를 입력하는 "네이티브 컴퓨터 사용"을 지원한다. 데스크톱 환경에서 실제 소프트웨어를 조작하는 능력을 측정하는 OSWorld 벤치마크에서 75.0%를 기록했는데, 인간 기준선이 72.4%니까 인간을 넘어선 셈이다. GPT-5.2가 47.3%였던 것과 비교하면 한 세대를 건너뛴 것 같은 도약이다.
컨텍스트 윈도우도 API 기준 100만 토큰까지 확장됐고, 추론 과정에서 토큰 사용량을 47%나 줄이는 데 성공했다. 쉽게 말해, 같은 문제를 풀면서 덜 수다스러워졌다는 건데 — 이건 곧 API 비용 절감으로 직결된다. 다만 27만 2천 토큰을 초과하는 입력에는 2배 요금이 붙으니, "100만 토큰 지원"이라는 숫자만 보고 무한정 밀어넣으면 요금 폭탄을 맞을 수 있다.
오류 감소도 눈에 띈다. 사용자가 사실 오류를 신고한 프롬프트 세트에서 테스트한 결과, 개별 주장 단위의 오류 발생 확률이 GPT-5.2 대비 33% 줄었고, 전체 응답에 오류가 포함될 확률은 18% 감소했다. 할루시네이션(AI가 그럴듯한 거짓말을 지어내는 현상)이 LLM의 아킬레스건이었던 걸 감안하면 의미 있는 진전이다.
근데 진짜 최강인가? Claude랑 Gemini를 놓고 보면 이야기가 달라진다
솔직히 내가 GPT-5.4 발표를 보면서 가장 먼저 든 생각은 "그래서 Claude 이기는 거야?"였다. 결론부터 말하면, 아무도 전 분야를 석권하지 못한다.
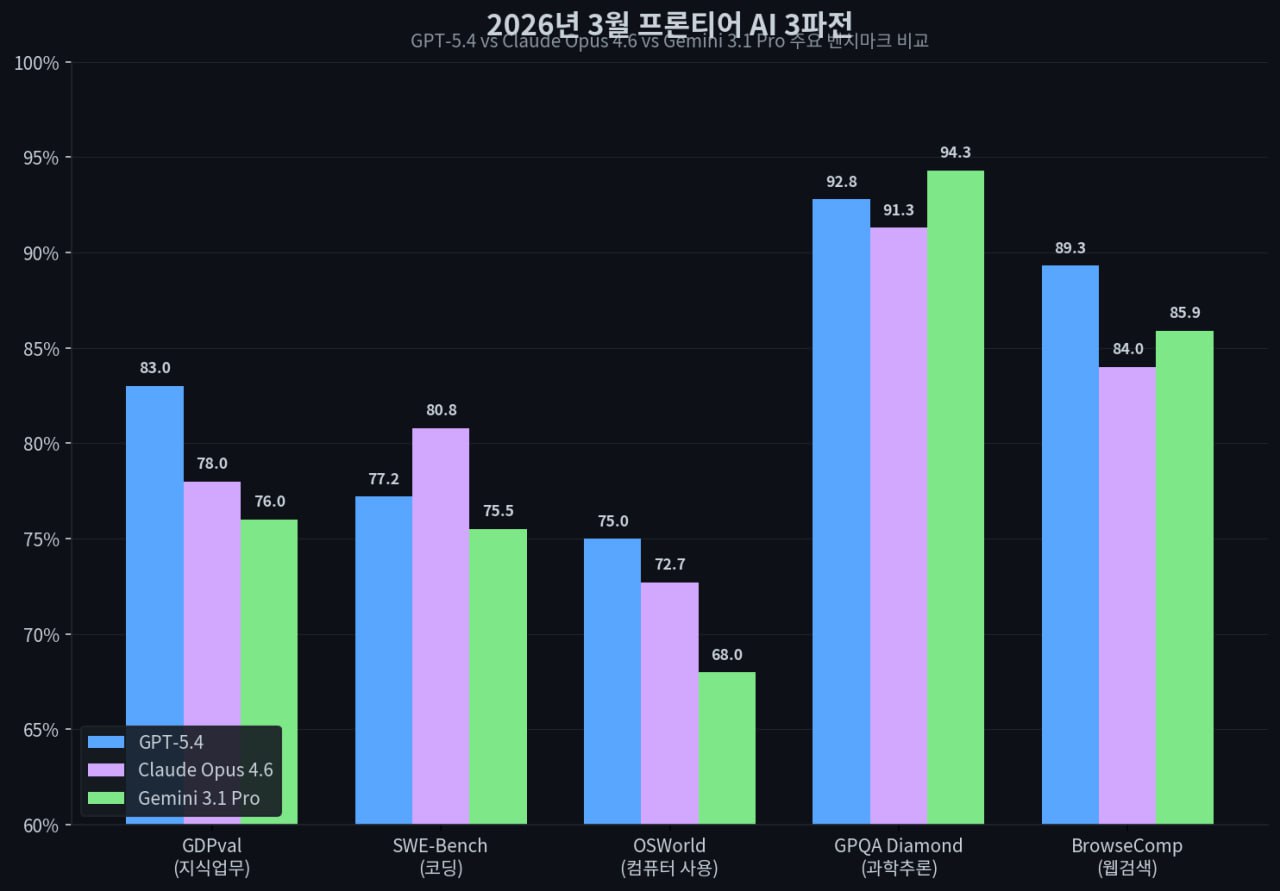 GPT-5.4 vs Claude Opus 4.6 vs Gemini 3.1 Pro. 각 모델이 강한 영역이 다르다
GPT-5.4 vs Claude Opus 4.6 vs Gemini 3.1 Pro. 각 모델이 강한 영역이 다르다GPT-5.4가 확실히 이기는 영역은 지식 업무(GDPval 83%)와 컴퓨터 사용(OSWorld 75%), 그리고 웹 검색(BrowseComp 89.3%)이다. 반면 코딩의 정석이라 할 수 있는 SWE-Bench에서는 Claude Opus 4.6이 80.8%로 GPT-5.4의 77.2%를 여전히 앞선다. 과학 추론에서는 Gemini 3.1 Pro가 GPQA Diamond 94.3%로 압도적이다.
재밌는 건 SWE-Bench Pro라는 더 어려운 변형 벤치마크에서는 GPT-5.4가 57.7%로 Claude의 약 45%를 오히려 크게 이긴다는 점이다. 쉬운 문제에서는 Claude가 낫고, 어려운 문제에서는 GPT가 낫다? 개발자 커뮤니티에서도 의견이 갈리는 부분인데, 실무에서 느끼는 체감은 "복잡한 리팩토링이나 멀티파일 디버깅은 아직 Claude가 한 수 위"라는 쪽이 우세하다. Claude의 Agent Teams 기능 — 여러 AI 인스턴스가 팀을 이뤄 코드 리뷰, 테스트, 문서화를 병렬로 처리하는 — 도 OpenAI 쪽에는 아직 없는 차별화 무기다.
나는 이 상황이 오히려 건강하다고 본다. 2026년 3월 현재, 프론티어 모델 세 개가 벤치마크 대부분에서 2~3%포인트 안에 몰려 있다. Artificial Analysis의 종합 지능 지수에서도 GPT-5.4와 Gemini 3.1 Pro가 57점으로 동률, Claude Opus 4.6이 53점으로 바짝 뒤쫓는 구도다. 기술 격차보다 가격과 사용자 경험이 선택의 기준이 되는 시대가 온 거다.
샘 알트먼은 만족하고, 사용자는 반반
샘 알트먼은 GPT-5.4 출시 이틀 뒤 소셜미디어에 "내가 지금까지 대화해본 모델 중 가장 좋다"고 극찬을 쏟아냈다. "한동안 모델 개성이 아쉬웠는데 드디어 방향이 맞아가고 있다"는 코멘트도 덧붙였다. GPT-5가 처음 나왔을 때 "차갑다", "영혼이 없다"는 혹평이 쏟아졌고 GPT-4o 팬들이 대거 이탈했던 걸 의식한 발언이다.
실제 사용자 반응도 이전보다는 확실히 좋아졌다. 코딩 성능은 "체감상 한 단계 올라갔다"는 평가가 많고, 특히 Thinking 모드에서 작업 계획을 먼저 보여주고 중간에 방향 수정이 가능한 기능은 실무에서 꽤 유용하다는 피드백이 나온다.
그런데 약점도 분명하다. 알트먼 스스로가 인정한 3가지가 있는데 — UI 생성 시 디자인 감각이 Claude나 Gemini보다 떨어진다는 점, OpenClaw와의 호환성 문제, 그리고 보안 가드레일이 과도하게 작동해서 정상적인 요청까지 거부하는 문제다. 세 번째가 특히 짜증나는 부분인데, 완전히 합법적이고 정상적인 질문을 던졌는데 "해당 요청은 처리할 수 없습니다"라는 답이 돌아오는 경험은 실제로 꽤 빈번하다는 후기가 올라오고 있다.
한국 사용자들 사이에서는 좀 독특한 반응이 나온다. GPT-5가 처음 나왔을 때 한국어 능력이 처참해서 "4o 돌려달라"는 아우성이 터졌었는데, 5.4에 와서는 "천지차이"라는 평가가 나무위키나 커뮤니티에서 보인다. 다만 HLE(인류 마지막 시험) 점수가 39.8%로 Gemini 3.1 Pro의 45.9%에 미치지 못했다는 점은 한경 보도에서도 짚었듯 "4개월 준비치고 기대에 못 미쳤다"는 평가의 근거가 된다.
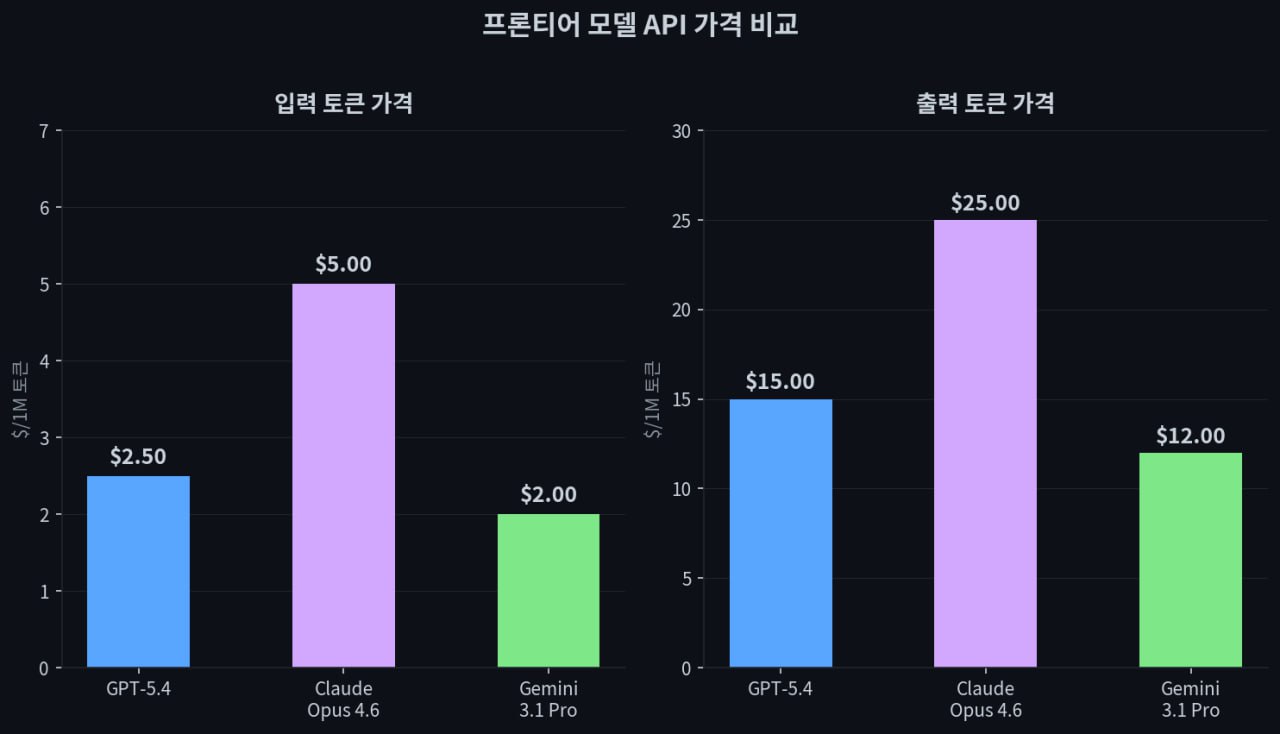
 API 토큰 가격 비교. GPT-5.4는 Claude 대비 절반 수준, Gemini보다는 약간 비싸다
API 토큰 가격 비교. GPT-5.4는 Claude 대비 절반 수준, Gemini보다는 약간 비싸다가격은 GPT-5.4의 확실한 강점이다. 입력 토큰 기준 100만 토큰당 2.50달러로, Claude Opus 4.6의 5달러 대비 절반이다. 출력 토큰도 15달러 대 25달러. 토큰 효율까지 47% 개선된 걸 감안하면, 같은 작업을 시킬 때 실제 비용 차이는 더 벌어진다. Gemini 3.1 Pro(입력 2달러, 출력 12달러)가 가격으로는 여전히 가장 저렴하지만, 성능 대비 가성비를 따지면 GPT-5.4가 상당히 매력적인 위치에 있다.
내가 보는 GPT-5.4의 진짜 의미
기술적 스펙보다 더 중요한 건 이 모델이 보여주는 방향성이다.
GPT-5.4는 AI의 역할이 "질문에 답하는 도구"에서 "업무를 실행하는 직원"으로 넘어가고 있다는 신호다. 컴퓨터를 직접 조작하고, 엑셀에 플러그인 형태로 들어가고, 100만 토큰의 맥락을 유지하면서 장시간 작업을 수행한다. 이건 단순한 챗봇 업그레이드가 아니다.
한국경제에서도 "이젠 제미나이에 안 되네"라는 제목을 뽑았는데, 나는 그 프레이밍이 핵심을 빗겨갔다고 본다. 진짜 질문은 "어떤 모델이 1등이냐"가 아니라, **"AI가 사람 일자리의 83%를 전문가 수준으로 해낼 수 있다는 게 우리한테 무슨 의미냐"**다. 한경 기사도 HLE(인류 마지막 시험) 점수에서 제미나이에 졌다는 걸 짚었는데, 그건 범용 지능 테스트고 — 실무 업무 수행에서는 이미 인간 전문가를 넘어선 영역이 나타나기 시작했다는 게 더 큰 이야기다.
OpenAI가 국방부 계약 논란, 사용자 이탈, Claude의 추격 속에서 GPT-5.4를 꺼내든 건 절박함의 산물일 수 있다. 하지만 모델 자체의 완성도는 인정해야 한다. 추론, 코딩, 컴퓨터 사용을 하나로 합친 최초의 진짜 "올인원" 프론티어 모델이라는 타이틀은 과장이 아니다.
다만 나는 이런 말도 해야 한다고 생각한다. ChatGPT Plus 월 20달러를 내고 있는 일반 사용자가 GPT-5.4에서 체감할 변화는 생각보다 크지 않을 수 있다. 무료 사용자는 자동 라우팅으로 가끔 5.4에 연결될 뿐, 직접 선택은 불가능하다. 이 모델의 진짜 수혜자는 API로 에이전트를 만드는 개발자, 그리고 엑셀과 코덱스 위에서 복잡한 업무 자동화를 구축하려는 기업이다. OpenAI CFO 사라 프라이어가 "올해 안에 기업 고객 비중을 50%까지 끌어올리겠다"고 말한 것도 이 맥락에서 읽어야 한다. "AI 직원 시대"라는 거창한 수식어는 맞을 수 있지만, 그 직원을 뽑아 쓸 수 있는 건 아직 기업 쪽이라는 현실도 같이 봐야 한다.
한 가지 더. GPT-5.2 Thinking은 6월 5일에 완전히 은퇴한다. 지금 5.2에 의존하는 워크플로가 있다면 전환 계획을 세워둘 필요가 있다.
결국 2026년 AI 모델 전쟁의 진짜 승자는 하나의 모델이 아닐 것이다. 코딩은 Claude, 지식 업무는 GPT-5.4, 가성비 추론은 Gemini — 작업에 따라 모델을 갈아 끼우는 멀티모델 전략이 가장 합리적인 선택이 되는 시대가 이미 와 있다.
참고 자료: OpenAI, TechCrunch, Fortune, VentureBeat, 한국경제, ZDNet Korea, AI타임스, Artificial Analysis